Inteligencia Artificial – Historia – Conceptos y Usos actuales. Material Introductorio para el encuentro sobre IA y el Asistente GPT de Consensos del Gabinete Multisectorial, organizado por la Multisectorial Federal de la República Argentina, que tendrá lugar este Jueves 28 de Noviembre para las militancias multisectoriales inscriptas en todo el país. La charla estará a cargo de María del Carmen Romano.
PDF completo del texto introductorio luego de estos párrafos finales. Se adjunta Audiolibro del Documento Completo en PDF.
Por Analía Mesa para Argentina en Red
Importante encuentro de presentación del modelo de prueba que la Multisectorial Federal puso a disposición de las militancias. El Asistente de Consensos del Gabinete Multisectorial sobre el que siguen cargando material producido por los equipos durante 2024. Este es el Video en que se agradece la alta participación inscripta para mañana a las 20:00 hs.
Lic. María del Carmen Romano
Grandes Modelos de Lenguaje
Los grandes modelos de lenguaje (LLM, Large Language Models) consisten en tecnología de IA avanzada que se centra en comprender y analizar texto. Son más precisos que los algoritmos de aprendizaje automático tradicionales, porque pueden
comprender las complejidades del lenguaje natural. Para ello, los grandes modelos de lenguaje requieren una gran cantidad de datos de entrenamiento, como libros y artículos, para aprender el funcionamiento del lenguaje. Pueden generar respuestas significativas y proporcionar información valiosa procesando enormes cantidades de texto. Los LLM son ahora codiciados para tareas de traducción, de respuesta a preguntas y para completar textos. Con más avances, podemos esperar modelos de lenguaje incluso más potentes en el futuro.
¿Cuál es el proceso de entrenamiento de los grandes modelos de lenguaje
(LLM)?

El proceso de entrenamiento de los grandes modelos de lenguaje (LLM) se
compone de varios pasos:
- Recopilación de datos: se recopila un conjunto de datos de texto diverso
procedente de varios orígenes. - Preprocesamiento: se limpian y estandarizan los datos del texto
recopilado. - Tokenización: se divide el texto preprocesado en unidades más
pequeñas, llamadas «tokens». - Selección de arquitectura: se elige la arquitectura de aprendizaje
profundo adecuada, como un modelo transformador. - Entrenamiento: el propio proceso de entrenamiento por el que el
modelo aprende los datos. - Mejora de los resultados: se optimiza el modelo introduciendo ajustes
precisos. - Evaluación: se evalúan los resultados y la precisión del modelo.
- Implementación: se implementa el modelo en un sistema en
funcionamiento para su uso. - ¿Qué es una red neuronal?
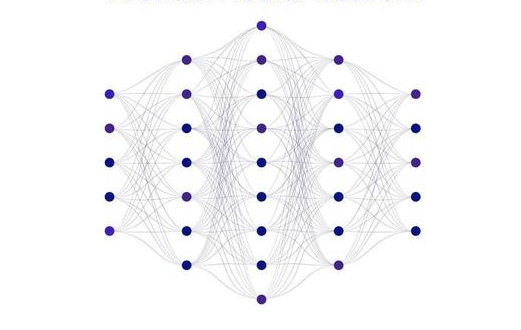
Una red neuronal es un método de la inteligencia artificial que enseña a las
computadoras a procesar datos de una manera similar a como lo hace el cerebro
humano. Se trata de un tipo de proceso de machine learning llamado aprendizaje
profundo, el cual utiliza los nodos o las neuronas interconectados en una estructura de
capas que se parece al cerebro humano. Crea un sistema adaptable que las
computadoras utilizan para aprender de sus errores y mejorar continuamente. De esta
forma, las redes neuronales artificiales intentan resolver problemas complicados, - 8 como la realización de resúmenes de documentos o el reconocimiento de rostros, con
mayor precisión.
¿Cómo funcionan las redes neuronales?
El cerebro humano es lo que inspira la arquitectura de las redes neuronales. Las células
del cerebro humano, llamadas neuronas, forman una red compleja y con un alto nivel
de interconexión y se envían señales eléctricas entre sí para ayudar a los humanos a
procesar la información. De manera similar, una red neuronal artificial está formada
por neuronas artificiales que trabajan juntas para resolver un problema. Las neuronas
artificiales son módulos de software, llamados nodos, y las redes neuronales
artificiales son programas de software o algoritmos que, en esencia, utilizan sistemas
informáticos para resolver cálculos matemáticos.
¿Cuáles son los tipos de redes neuronales?
Las redes neuronales artificiales pueden clasificarse en función de cómo fluyen los
datos desde el nodo de entrada hasta el nodo de salida. A continuación, se indican
varios ejemplos:
Redes neuronales prealimentadas
Las redes neuronales prealimentadas procesan los datos en una dirección, desde el
nodo de entrada hasta el nodo de salida. Todos los nodos de una capa están
conectados a todos los nodos de la capa siguiente. Una red prealimentada utiliza un
proceso de retroalimentación para mejorar las predicciones a lo largo del tiempo.
Algoritmo de retropropagación
Las redes neuronales artificiales aprenden de forma continua mediante el uso de
bucles de retroalimentación correctivos para mejorar su análisis predictivo. En pocas
palabras, puede pensar en los datos que fluyen desde el nodo de entrada hasta el
nodo de salida a través de muchos caminos diferentes en la red neuronal. Solo un
camino es el correcto: el que asigna el nodo de entrada al nodo de salida correcto.
Para encontrar este camino, la red neuronal utiliza un bucle de retroalimentación que
funciona de la siguiente manera: - Cada nodo intenta adivinar el siguiente nodo de la ruta.
- Se comprueba si la suposición es correcta. Los nodos asignan valores de peso
más altos a las rutas que conducen a más suposiciones correctas y valores de
peso más bajos a las rutas de los nodos que conducen a suposiciones
incorrectas. - Para el siguiente punto de datos, los nodos realizan una predicción nueva con
las trayectorias de mayor peso y luego repiten el paso 1.
¿Qué es el prompting en español? - 9 En términos simples, el prompting es una técnica que utiliza preguntas u otro tipo de
estímulos para motivar a las personas a realizar una determinada acción o para que
recuerden algo en particular. En otras palabras, el prompting es una forma de llamar la
atención de las personas y hacer que actúen de cierta manera.
¿Qué son los prompts en IA?
Un prompt en el contexto de la inteligencia artificial es una instrucción o texto inicial
proporcionado a una herramienta generativa de IA para dirigir la generación de
respuestas o resultados específicos.
La inteligencia artificial y los modelos de lenguaje grande (LLM) están cambiando la
forma en que interactuamos con la tecnología.
En 2024, los modelos más destacados son ChatGPT de OpenAI, Microsoft Copilot,
Claude de Anthropic y Google Gemini.
Comparativa Final: Modelos LLM según parámetros técnicos y de uso - Mejor para procesamiento multimodal: GPT-4 (ChatGPT).
- Mejor relación costo-rendimiento: GPT-4o mini.
- Mejor integración con herramientas de productividad: Microsoft Copilot.
- Mejor para análisis de textos largos: Claude de Anthropic.
- Mejor para generación de imágenes y conexión a internet: Gemini de Google.
Estructura de la IA
¿Cuáles son los componentes clave de la arquitectura de aplicaciones de IA?
La arquitectura de inteligencia artificial consta de cuatro capas fundamentales. Cada
una de estas capas utiliza tecnologías distintas para desempeñar una función
determinada. Lo siguiente es una explicación de lo que ocurre en cada capa.
Capa 1: capa de datos
La IA se basa en varias tecnologías, como machine learning, procesamiento del
lenguaje natural y reconocimiento de imágenes. Los datos son fundamentales para
estas tecnologías, que forman la capa fundamental de la IA. Esta capa se centra
principalmente en preparar los datos para las aplicaciones de IA. Los algoritmos
modernos, especialmente los de aprendizaje profundo, exigen enormes recursos
computacionales. Por lo tanto, esta capa incluye un hardware que actúa como una
subcapa, que proporciona una infraestructura esencial para el entrenamiento de los
modelos de IA. Puede acceder a esta capa como un servicio completamente
gestionado proporcionado por un proveedor de nube externo.
Capa 2: capa de esquemas de ML y algoritmos - 10 Los ingenieros crean esquemas de ML en colaboración con expertos en datos para
satisfacer los requisitos de casos de uso empresariales específicos. Luego, los
desarrolladores pueden usar funciones y clases prediseñadas para construir y entrenar
modelos fácilmente. Algunos ejemplos de estos esquemas son TensorFlow, PyTorch y
scikit-learn. Estos esquemas son componentes vitales de la arquitectura de la
aplicación y ofrecen funcionalidades esenciales para crear y entrenar modelos de IA
con facilidad.
Capa 3: capa de modelos
En la capa de modelos, el desarrollador de la aplicación implementa el modelo de IA y
lo entrena utilizando los datos y algoritmos de la capa anterior. Esta capa es
fundamental para las capacidades de toma de decisiones del sistema de IA.
Estos son algunos de los componentes clave de esta capa.
Estructura de modelos
Esta estructura determina la capacidad de un modelo, que comprende capas,
neuronas y funciones de activación. Según el problema y los recursos, se puede elegir
entre redes neuronales de retroalimentación, redes neuronales convolucionales (CNN)
u otras.
Parámetros y funciones de modelos
Los valores aprendidos durante el entrenamiento, como los pesos y los sesgos de las
redes neuronales, son cruciales para las predicciones. Una función de pérdida evalúa el
rendimiento del modelo y tiene como objetivo minimizar la discrepancia entre los
resultados pronosticados y los reales.
Optimizador
Este componente ajusta los parámetros del modelo para reducir la función de pérdida.
Varios optimizadores, como el descenso de gradiente y el algoritmo de gradiente
adaptativo (AdaGrad), tienen diferentes propósitos.
Capa 4: capa de aplicación
La cuarta capa es la capa de aplicación, que es la parte de la arquitectura de IA
orientada al cliente. Puede solicitar a los sistemas de IA que completen determinadas
tareas, generen información, proporcionen información o tomen decisiones basadas
en datos. La capa de aplicación permite a los usuarios finales interactuar con los
sistemas de IA.
¿Qué es el machine learning?
Los algoritmos de machine learning son algoritmos matemáticos que permiten a las
máquinas aprender imitando la forma en la que aprendemos los humanos, aunque el
machine learning no son solo algoritmos es también el enfoque desde el que se aborda - 11 el problema. El machine learning es básicamente una forma de conseguir inteligencia
artificial.
¿Qué es el deep learning?
El deep learning (DL) forma parte del aprendizaje automático. De hecho, se puede
describir como la nueva evolución del machine learning. Se trata de un algoritmo
automático que imita la percepción humana inspirada en nuestro cerebro y la
conexión entre neuronas. El DL es la técnica que más se acerca a la forma en la que
aprendemos los humanos.
La mayoría de los métodos de deep learning usan arquitectura de redes neuronales. Es
por eso por lo que a menudo se conoce al deep learning como “redes neuronales
profundas” o “deep neural networks”. Se le conoce como “deep” en referencia a las
capas que tienen estas redes neuronales.
¿Cuál es la diferencia entre ambos?
Explicado de forma simple, tanto el machine learning como el deep learning imitan la
forma de aprender del cerebro humano. Su principal diferencia es, pues, el tipo de
algoritmos que se usan en cada caso, aunque el deep learning se parece más al
aprendizaje humano por su funcionamiento como neuronas. El machine learning
acostumbra a usar árboles de decisión y el deep learning redes neuronales, que están
más evolucionadas. Además, ambos pueden aprender de forma supervisada o no
supervisada

Audiolibro del Documento Completo
PDF del Documento Completo
hola